.svg)

.svg)

March 28, 2026
What it takes to make Mesh work at scale
The following is by Mesh Frontend Engineer, Balraj A
Building a payments system is hard. Building one that works across 300+ platforms is harder. At that scale, you’re no longer just integrating APIs–you’re designing a system that can survive inconsistency, failure, and constant change.
That was the challenge we faced at Mesh. What started as a series of integrations quickly became something else: a coordination problem across hundreds of systems that were never designed to work together.
In this article, I explain how we approached that problem and what it took to make Mesh work at scale.
The Problem: There’s no “standard” in payments
On paper, integrations sound simple: You connect to a platform and then move money from A to B. In reality, every platform is its own universe with different authentication models, asset representations, failure modes, compliance requirements, and latency and reliability characteristics.
Consider something as simple as a “balance”, which across platforms can mean:
- Available balance
- Settled balance
- Spendable balance (after holds, fees, etc.)
Now multiply this complexity across 300+ platforms and the question becomes obvious: how do you create a system that stays consistent on top of inherently inconsistent foundations?
That was Mesh’s big challenge, and to solve it we approached the problem methodically, breaking it down into five key steps.
Step 1: Standardize everything
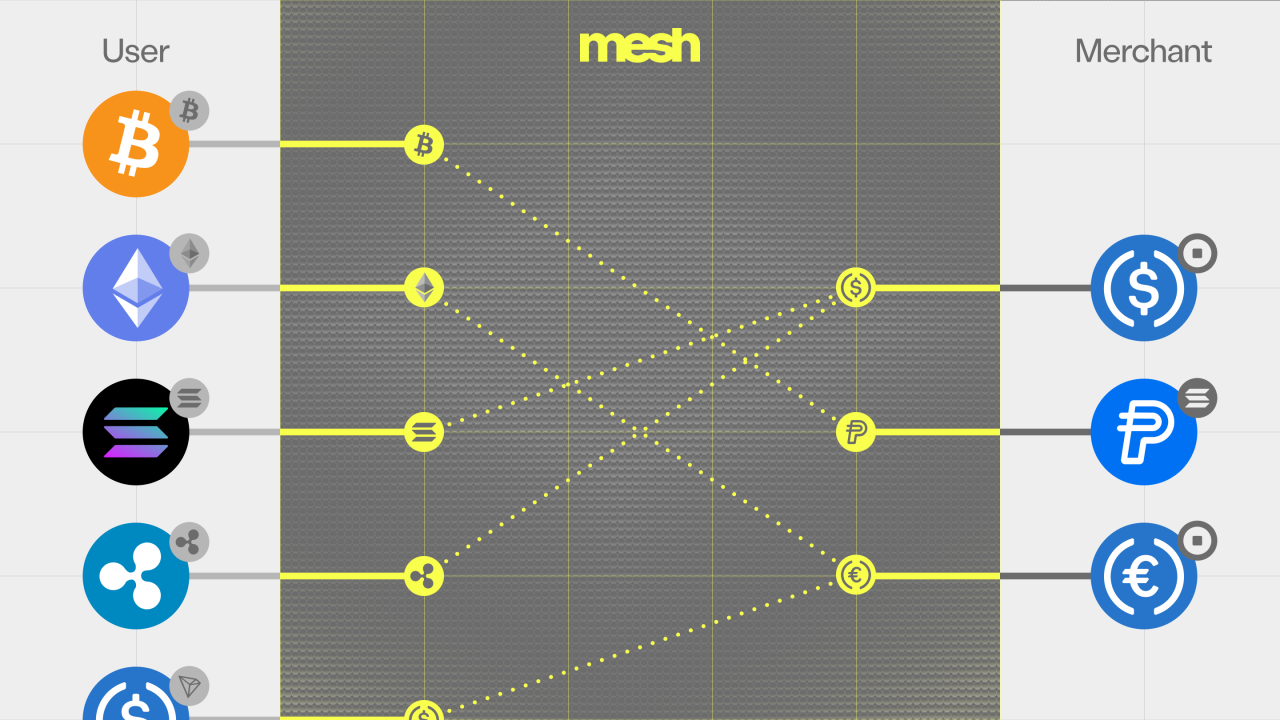
Every platform must be translated into a common internal model.
We standardized:
- Assets: unified representation across crypto and fiat
- Accounts: consistent structure regardless of provider
- Transactions: every lifecycle is pending → processing → settled → failed
- Errors: consistent categorization across all platforms
Without this standardization, logic becomes platform-specific, edge cases explode, and (most importantly) scaling becomes impossible.
Step 2: Build an orchestration layer
Once inputs are standardized, you can start making decisions. Instead of “Send payment via platform X,” the system can determine the best way to move value from A to B.
This introduces:
- Routing logic: which rail to use
- Fallbacks: what happens if things fail
- Optimization: fees, speed, reliability
The orchestration layer is what turns integrations into infrastructure. Without it, you’re just connecting systems, but with it you’re coordinating them.
Step 3: Design for failure
Most systems assume success, but at a certain scale failure is the default:
- APIs timeout
- Webhooks arrive late (or never)
- Balances drift
- Transactions get stuck
Instead of asking “How do we make this work?” we asked “How do we make this recoverable?”
That meant designing the system so failures were expected, not exceptional. Operations could be retried safely, state could always be reconciled, processes reacted to events rather than requests, and no single error could disrupt the overall flow.
Step 4: Abstract complexity for the user
While the system is complex internally, it must be simple on the outside or the user will drop off.
Users don’t care which chain was used, which provider processed the transaction, or how many steps it took. They just want their payment to go from A to B.
To abstract complexity, the product layer focuses on three things:
- Deterministic UX: users always see a predictable, clear experience
- Clear states: users know what’s happening even if the underlying system is messy
- Fast feedback loops: users get immediate updates, even if final settlement takes longer
This is the point where engineering and product really come together: the goal is to make a complex system feel effortless for the user.
Step 5: Accept the system is never “done”
With 300+ platforms, change is constant. APIs evolve, new assets are added, and regulations shift. The system must be designed to handle this flux. It must be:
- Modular: integrations can be swapped
- Extensible: new platforms don’t break existing logic
- Observable: you know what’s breaking, where, and why
Of all the steps, this one is the hardest. It’s relatively easy to build a system–the challenge is keeping it stable while the world around it keeps changing.
Closing thoughts
At small scale, payments are about moving money. At large scale, they’re about managing uncertainty. The role of infrastructure is to absorb that unpredictability and turn it into something reliable, consistent, and intuitive to the end user.
Building Mesh taught us that the best payment systems aren’t the ones that are fastest or flashiest–they’re the ones that keep working despite thousands of variables that are constantly changing. In other words, reliability is what defines success at scale.
Want more like this? Subscribe to Mesh Weekly.


.png)
.png)

.png)



.png)


.png)



.png)




.png)






%20(1).png)





























.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)